
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 파이썬
- python
- 백준
- 타입스크립트 올인원
- 리액트
- til
- programmers
- 2주 프로젝트
- 리트코드
- 타임어택
- 자바스크립트
- 코드스테이츠
- 프로그래머스
- SQL 고득점 Kit
- 4주 프로젝트
- 토익
- 손에 익히며 배우는 네트워크 첫걸음
- codestates
- 타입스크립트
- javascript
- 제로초
- js
- 리덕스
- HTTP
- 알고리즘
- 회고
- LeetCode
- 코어 자바스크립트
- 렛츠기릿 자바스크립트
- 정재남
- Today
- Total
Jerry
CS fundamentals 질문에 답해보기! (스압 주의!) 본문
😁 이번 시간에는 일반 개발 지식 3개와 컴퓨터 공학 기초 11개, os 지식 8개, 문자열 지식 5개를 정리해보는 시간을 갖겠습니다!
일반 개발 지식
Q1. 객체 지향 프로그래밍에 대해서 설명하세요.
A. 객체지향 프로그래밍은 전통적인 절차 지향 프로그래밍과 다르게 실제 세계의 사물을 인지하는 방식을 프로그래밍에 접목하려는 사상입니다. 추상화라고도 합니다. 사물에 대한 모델을 만들기 위해 클래스와 객체를 이용해 만듭니다.

Q. 절차지향 프로그래밍은 무엇이고, 실제 사물을 인지하는 방식을 접목하면 뭐가 좋나요?
A. 절차지향절차 지향 프로그래밍은 절차(프로시저, 함수)라고 불리는 개념에 기반한 구조화된 프로그래밍에서 유래한 프로그래밍 모델입니다. 객체지향은 객체로 나뉘듯이, 절차 지향 프로그래밍은 함수로 나누어 탑다운식 진행을 합니다.
객체지향 프로그래밍은 기존 객체의 특성을 상속받은 새로운 객체 코드이기 때문에 수정과 유지하기 수월합니다.
Q. 왜 유지 보수가 수월할까요?
A. 아무래도 쉽게 읽을 수 있고 변경할 수 있는 코드가 유지 보수하기 편하고 비용도 줄어듭니다. 절차 지향 프로그래밍은 여러 프로시저(함수)가 데이터를 조작하거나 사용하는 방식으로 데이터의 변화를 일으켜 코드(프로시저)의 변화를 불러옵니다.
이에 비해, 객체지향 프로그래밍은 데이터와 기능을 함께 담고 있는 객체들이 데이터 공유는 최대한 주고받지 않고 상호 간 기능을 실행 달라고 하는 요청하는 방식으로 구현되어, 내부 데이터를 노출하지 않아 데이터 변화에 따른 유지보수 비용이 절차 지향에 비해 작아지는 것이다.
Q. 객체지향 프로그래밍의 4가지 특징에 대해 이야기 해보세요.
A. 4가지 특징으로,
필요한 정보만을 간소화하는 것을 의미하는 추상화가 있습니다. (모델링)
객체에 필요한 데이터나 기능을 책임이 있는 객체에 그룹화시켜주는 캡슐화가 있습니다.(정보 은닉)
상위 클래스의 기능을 하위 클래스가 사용할 수 있는 개념인 상속이 있습니다. (코드 재사용 + 확장)
하나의 객체가 여러 가지 타입을 가질 수 있는 특징인 다형성이 있습니다. (사용 편의)
Q. 각 특징의 예시를 말씀해보세요.
A. 추상화의 예로, 정리된 지하철 노선도가 있고(실제 지형도보다 지하철역 간 상대 위치가 중요시), 클래스가 있습니다.
캡슐화의 예로, 은닉화가 있습니다. 내부 로직이나 변수들을 감추고 외부에는 기능(api)만 제공합니다. 모듈화가 있습니다.
상속의 예로, 부모 객체의 변수와 함수를 그대로 물려받을 수 있듯이, 리액트 클래스 컴포넌트 재사용이 있습니다.
다형성의 예로, 같은 객체임에도 상황에 따라 다르게 동작할 수 있는 것이며, 리액트 스위치 만들기 예제: +, -기능을 가지고 있는 함수가 있습니다.
Q. 다형성 관련 개념으로 오버 로딩과 오버 라이딩이 있는데, 이에 대해 설명해보세요.
A. 오버 로딩은 같은 이름의 메서드를 여러 개 가지면서 매개 변수를 다르게 정의하는 것, (매소드 이름 같음)
오버 라이딩은 상위 클래스가 갖고 있는 메서드를 하위 클래스에서 재정의해 사용하는 것입니다. (매개 변수 타입, 매개변수 다름)
Q. 상속과 다형성의 차이가 뭘까요?
A. 상속은 상위 클래스의 모든 것을 하위 클래스가 가지고 있으며, 그대로 사용 및 커스터마이징 할 수 있는 것이고,
다형성은 한 행동(메서드)을 여러 방법으로 구현하고 상황에 따라 적당한 구현을 선택해서 쓸 수 있도록 해주는 기능을 제공하는 것입니다.
참고
자바캔 | https://bit.ly/3cex7Mu
DevAndy | https://bit.ly/3g3gULj
Q2. 함수형 프로그래밍에 대해서 설명하세요.
A. 함수형 프로그래밍은 선언형 프로그래밍으로 순수 함수를 조합하고 소프트웨어를 만드는 방식입니다.
함수형 프로그래밍은 대입문을 사용하지 않아, 변수에 값이 할당되면 그 이후로 절대 변하지 않습니다. 이런 부수 효과(side effect)가 없는 순수 함수를 1급 객체로 간주하여 파라미터로 넘기거나 반환 값으로 사용할 수 있으며, 참조 투명성을 지킬 수 있습니다. 이에 대한 예로, 클로저가 있습니다. (+하스켈, 리스프)
Q. 선언형 프로그래밍은 무엇인가요?
A. 프로그래밍 패러다임은 프로그래머에게 프로그래밍의 관점을 갖게 하고 코드를 어떻게 작성할지 결정하는 역할을 하는데요. 선언형 프로그래밍은 '어떻게 할 건인지(How)를 나타내기보다는 무엇(What)을 할 건지를 설명하는 방식'입니다.
(참고: 명령형 프로그래밍은 '무엇(What)을 할 것인지 나타내기보다 어떻게(How) 할 건지를 설명하는 방식'입니다.
종류로, 수행되어야 할 순차적인 처리 과정을 포함하는 방식인 절차 지향 프로그래밍(C, C++)과 객체들의 집합으로 프로그램의 상호작용을 표현하는 객체지향 프로그래밍(C++, Java, C#)이 있습니다.)

Q. 부수 효과와 1급 객체가 무엇을 이야기하는 건가요?
A. 부수 효과란 '(1) 변수의 값이 변경되거나 자료 구조를 제자리에서 수정, (2) 객체 필드 값 설정, (3) 예외나 오류 시 실행이 중단, (4) 콘솔 또는 파일 I/O 발생'을 의미합니다. 이런 부수효과를 제거한 함수를 순수 함수라고 부릅니다.
다시 풀어서 이야기해보면,
(1) 변수의 변형이 없다. (변수를 사용하지 않는다)
(2) 어떤 함수에 특정 값을 입력하면 그에 따른 출력이 발생하며, 같은 값을 입력하면 항상 그에 대한 출력도 같다. (의존성)
(3) 예외가 발생하지 않는다.
(4) 콘솔 또는 어떤 디바이스에도 출력하지 않는다.
(5) 파일, 데이터베이스, 네트워크 어디에도 데이터를 쓰지 않는다.
1급 객체란, 1급 시민의 조건을 충족하는 객체입니다. JS에서 객체는 1급 시민입니다.
1급 시민의 조건은 '1. 변수를 담을 수 있어야 하며, 2. 함수(혹은 메서드)의 인자(혹은 매개변수)로 전달할 수 있어야 하며, 함수(혹은 메서드)의 반환 값으로 전달'할 수 있어야 합니다.
var a = 1 // 변수에 담을 수 있다.
function f1 (num) { // 매개변수로 전달할 수 있다.
var b = num + 1
return b // return으로 전달할 수 있다.
}
console.log(f1(a)) // result: 2
결국, 1급 객체란 1급 시민의 조건을 가진 객체이므로 결국, 객체를 의미합니다.
var a = {msg: 'a는 1급 객체입니다.'} // 변수에 담을 수 있다.
function f1 (a) { // 매개변수로 전달할 수 있다.
var b = a
b.msg2 = '이것은 2번째 메세지입니다.'
return b // return으로 전달할 수 있다.
}
console.log(f1(a)) // result : {msg: 'a는 1급 객체입니다.', b: '이것은 2번째 메세지입니다.'}
또한, JS에서 함수는 prototype을 통해 object를 상속받아 사용하기 때문에, 함수도 객체라는 것을 의미합니다.
결국, 함수도 1급 객체라고 볼 수 있습니다.
여기서, 함수가 1급 객체라는 것이 중요한 것은 왜일까요?
=> 고차 함수가 가능하는 점, 클로져와 만나 커링과 메모이제이션이 가능해지기 때문입니다.
(*고차 함수란, 함수를 인자로 전달받거나 함수를 결과로 반환하는 함수)
tmi
JS의 함수는 1급 함수여서, 아래 조건을 만족하는 게 됩니다.
1. 함수를 변수에 할당할 수 있다.
2. 함수를 매개변수로 전달할 수 있다.
3. 함수는 함수를 반환할 수 있다.
// 변수에 함수를 할당
var a = function (num) {
return num * num
}
// 매개변수로 함수를 전달
function b (fun) {
var num = fun(10)
// return 값으로 함수를 사용
return function (num2) {
var num2 = num2 || 2
return num * num2
}
}
// b에 a라는 함수 전달했으며, b는 다시 함수를 반환한다.
// 결국 c도 함수로 사용할 수 있다.
var c = b(a)
console.log(c()) // result : 200
console.log(c(3)) // result : 300
그래서, 클로저도 사용할 수 있게 되었습니다.
var fn = function (){
var num = 1
return function () {
return num++
}
}
var fn2 = fn()
console.log(fn2()) // 1
console.log(fn2()) // 2
console.log(fn2()) // 3
console.log(fn2()) // 4
console.log(fn2()) // 5fn을 실행함과 동시에, fn 속에 있는 num이 만들어져, fn2를 실행할 경에 fn의 num값을 다루게 되며, fn의 num은 소멸되지 않고 메모리에 계속 잔류하게 된다.
Q. 참조 투명성(Referential Transparency)을 지킬 수 있다는 것을 무엇을 이야기하는 건가요?
A. 동일한 인자에 대해 항상 동일한 결과를 반환한다는 것을 의미합니다. 결국, 참조 투명성을 통해 기존 값은 변경되지 않고 유지됩니다(Infinite Data).
Q. 함수형 프로그래밍의 특징이 무엇이 있을까요?
A. 일급 함수, 익명 함수, 클로져, 커링, 게으른 평가, 대수적 데이터 타입 같은 테크닉을 사용합니다...
더 이상 꼬리 질문하지 마... 끝이 안 보여...
출처
개발자 황준일 | https://bit.ly/3wTaMMu
bestalign's dev blog | https://bit.ly/2TsL3Mf
망나니개발자 | https://bit.ly/3cdgtNp
ruaa | https://bit.ly/3wO1l0w
Q3. git flow에 대해서 간략하게 설명하세요.
(Git은 작은 프로젝트부터 매우 큰 프로젝트까지 효율과 속도를 다루기 위해 고안된 무료이자 오픈소스 분산 버전 관리 시스템 )
A. git-flow는 프로젝트 버전 관리 시스템인 git으로 개발할 때 사용되는 방법론입니다. git-flow에는 두 가지 선택 상황이 있습니다.
하나는 브랜치를 이용한 버전 관리, 둘 Fork와 Pull requests를 이용한 버전 관리가 있습니다.
첫째, 브랜치를 이용한 버전 관리는 5가지 브랜치를 사용해서 운영합니다. master, develop, feature, release, hotfix가 있으며, master는 기준이 되는 브랜치로 제품을 배포하는 브랜치입니다. develop 브랜치는 개발 브랜치입니다. feature 브랜치는 단위 기능을 개발하는 브랜치입니다. 기능 개발이 완료되면 develop 브랜치에 합칩니다. release 브랜치는 배포를 위해 master 브랜치로 보내기 전 QA 하기 위한 브랜치입니다. hotfix 브랜치는 master 브랜치로 배포 후, 버그가 발생 시 긴급 수정하는 브랜치입니다.
(master와 develop가 메인 브랜치, 나머지는 필요에 따라 운영되는 브랜치)

1. master 브랜치 -> 2. develop 브랜치 생성 -> 3. 기능 구현을 위해, feature 브랜치 생성 -> 4. 완료한 feature 브랜치는 검토 후, develop 브랜치에 merge -> 5. 모든 기능 완료 시, develop 브랜치를 release 브랜치로 만들어, QA를 함 -> 6. 모든 것이 완료되면, release 브랜치를 master 브랜치와 develop 브랜치로 보내기 -> 7. master 브랜치에서 버전 추가(태그 생성) 후, 배포 -> 8. 만약, 버그 발생 시, hotfixes 브랜치를 만들어 태그 생성 후 수정 배포
2번째, Fork, Pull requests를 활용한 버전 관리는 리액트나 부트스트랩 같이 규모가 있는 개발에 적합합니다.

Fork는 브로젝트를 통째로 복사하여, 내 저장소로 가져오는 방식입니다. 그 후, 개발 후에 Pull requests로 Fork 한 원래 저장소에 merge 요청을 하여 관리자의 승인에 따라 해당 기능을 붙일지 말지를 정합니다.
출처
UX 공작소 | https://uxgjs.tistory.com/183
컴퓨터 공학 기초, Number System
Q1. 왜 RAM이 하드디스크보다 비싸다고 생각하나요?
A. CPU가 처리할 데이터가 임시로 저장되는 곳인 RAM과 사용자가 실행하는 모든 프로그램에 대한 데이터를 저장하는 HDD 중에서, CPU와 일을 진행하는 RAM이고, HDD는 CPU가 처리할 정보나 처리한 정보를 RAM을 통해 저장합니다. 그래서 RAM을 주 기억장치라고 하고 HDD는 보조 기억장치라고 합니다.
RAM은 CPU의 속도에 비해 HDD의 속도가 너무 느리기 때문에, 이 둘의 속도 차이를 줄여 병목 현상을 줄이기 위해 만들어진 것이 메모리 반도체인 RAM(Random Acceess Memory)입니다.
이렇듯, CPU가 성능이 뛰어나도 저장매체 한계에서 그 성능을 발휘하기 위해서, CPU의 속도는 RAM의 역할에 따라 좌우된다고 볼 수 있습니다. 그래서 RAM이 HDD보다 비싸다고 생각합니다.
출처
Rapter's iNfo | https://bit.ly/3vMVhWj
Q2. RAM 메모리 주소는 왜 16진법으로 표현할까요?
A. 옛날 CPU는 정보를 처리하기 위한 최소 단위를 8비트(8bit)로 정하고 이것을 1바이트(1Byte)로 정의했습니다. 1바이트를 바이너리로 표시하면
1111 1111
총 8 자리이기 때문에 표현할 수 있는 수의 가짓수는 총 256가지입니다(2^8, 2의 8승).
이를 16진수로 표현하면 0xFF와 같이 나타낼 수 있게 됩니다. (16 + 16)
원리는, 16진법은 1~10까지는 10진수와 같고, 10부터 16까지 알파벳으로 나타납니다.
예를 들어, 11은 A, 13은 C, 16는 F로 표기합니다.
이렇게 1바이트를 16진수로 표현하면, F 문자 두 개를 사용해서 나타낼 수 있게 됩니다.
1바이트는 8비트로 이뤄지고, 8비트를 반으로 나누어 4비트씩 나누면
4비트는 최대 1에서 16까지 표현 가능합니다.
간편하고 일관성 있는 메모리 주소 작성이 가능해진다는 장점이 생깁니다.
(* 0x는 16진수라고 명시하는 표시)
출처
archiles | https://bit.ly/3wWgNry
일시불 | https://bit.ly/3wRoMX1
Q3. 32-bit 운영체제에서 4GB밖에 램을 사용할 수 없는 이유는 무엇인가요?
A. 컴퓨터에 실제 RAM이 얼마만큼 장착되어 있는가에 상관없이 32비트 운영체제 환경에서 각 프로그램은 32비트의 가상 메모리 공간을 사용하기 때문에 값을 기억할 수 있는 메모리의 용량은 최대 4G가 됩니다. (2^32 = 4,294,967,296 (4G))
실제로는 3GB 정도 인식하는데, 그 이유는 컴퓨터를 켤 때 PAM(Physical Address Map)에서 RAM, VGA 메모리 등의 메모리 장치들이 가지고 있는 정보로 일종의 색인을 만들어 윈도우에게 건네주는데...
PAM에서는 시스템 메모리뿐만 아니라 그래픽 카드, 랜카드 등의 여러 가지 메모리를 취급하여 윈도우에게 건네주어, 윈도우는 3GB의 메모리만 사용할 수 있게 된다.
출처: 해답을 찾기위해... | https://bit.ly/2Rs5h8g
Q4. IEEE 754 Single-precision floating-point format과 IEEE 754 double-precision floating-point format 중 무엇이 더 많은 저장용량을 차지하나요?
IEEE란 전기 전자 기술자 협회라는 전기전자공학 국제 조직이다. (이하, Institute of Electrical and Eletronics Engineers)
IEEE 754는 IEEE에서 개발한 컴퓨터에서 부동소수점을 표현하는 가장 널리 쓰이는 표준이다.
부동소수점(flating point) 이란, 떠돌이 소수점 방식이라고도 불리는데, 실수를 컴퓨터상에서 근사하여 표현할 때 소수점의 위치를 고정하지 않고 그 위치를 나타내는 수를 따로 적는 것으로 가수와 지수를 나누어 표현한다.

실제 사용되고 있는 부동 소수점 방식은 대부분 IEEE 754 표준을 따른다.
이 규격에서 실수를 32비트로 처리하는 단정밀도(single precision)에서는 부호 1비트, 지수부 8비트, 가수부 23비트를 사용하며,
64비트로 처리하는 배정밀도(double precision)에서는 부호 1비트, 지수부 11비트, 가수부 52비트를 사용한다.

IEEE 754 Single-precision floating-point format
Single-precision floating-point format은 컴퓨터 숫자 형식으로 보통 32비트 컴퓨터 메모리에서 점유하고 있다.

IEEE 754 double-precision floating-point format
Double-precision floating-point format은 컴퓨터 숫자 형식으로 보통 64비트 컴퓨터 메모리에서 점유하고 있다.
Double-precision floating-point은 대역폭 비용과 성능에도 불구하고, 단정밀도(single-precision) 부동 소수점을 넘는 넓은 범위 때문에 흔히 PC 형태로 사용되며, 일반적으로 2배가 더 걸린다고 알려져 있다.

C나 Java의 경우, 정수와 실수를 구분하여 int, long, float, double 등과 같은 다양한 숫자 타입이 존재한다. 하지만 자바스크립트는 독특하게 하나의 숫자 타입만 존재한다.
ECMAScript 표준에 따르면, 숫자 타입의 값은 배정밀도 64비트 부동소수점 형(double-precision 64-bit floating-point format : -(253 -1) 와 253 -1 사이의 숫자값)을 따른다. 즉, 모든 수를 실수를 처리하며 정수만을 표현하기 위한 특별한 데이터 타입(integer type)은 없다.
출처:
위키피디아 | https://bit.ly/3inpJ5b
위키피디아 | https://bit.ly/3w5Gara
위키피디아 | https://bit.ly/3ghW1vJ
MDN | https://mzl.la/2TLXkvA
위키피디아 | https://bit.ly/2RwZsGM
Poiemaweb | https://bit.ly/3zcs9JW
Q5. 16진수가 컴퓨터공학에서 자주 사용되는 이유에 대해서 설명해보세요.
A. 컴퓨터 내부 구조는 2진수를 사용한다. 10진수를 2진수로 변환과 2진수를 10진수로 변환과 다르게,
16진수를 2진수 사이의 변환은 계산을 하지 않아도 바로 알 수 있다. 16진수를 네 자리씩 끊어서 2진수로 변환할 수 있다.
2진수는 실제 데이터 저장 방식에 가장 근접한 표현 방식이지만, 사람 입장에서 보면 너무 숫자가 금방 늘어나는 단점이 있고,
16진수는 어떻게 보면, 10진수와 2진수의 중간, '사람도 적당히 보기 편하고 숫자도 너무 늘어나지 않는' 차선책이라고 볼 수 있다.
출처:
위키사전 | https://bit.ly/2T6hXlA
인프런 Q&A | https://www.inflearn.com/questions/102542
Q6. 컴파일러와 인터프리터의 차이가 무엇인가요?
컴파일러는 고수준 프로그래밍 언어를 기계 코드로 변환하는 컴퓨터 프로그램이다.
컴파일러는 사람이 읽기 쉬은 코드에서 컴퓨터 프로세서가 이해하는 언어(바이너리 1과 0비트)로 변환시킨다.
컴퓨터는 해당 작업을 수행하기 위해 기계 코드를 처리한다.
인터프리터는 각 고수준 프로그램 구문을 기계 코드로 변환하는 컴퓨터 프로그램이다.
인터프리터에는 소스 코드, pre-compiled 코드, 스크립트를 포함된다.
둘 다 고수준 언어를 기계 코드로 바꾼다는 공통점이 있지만,
컴파일러는 프로그램이 실행되기 전 코드를 한 번에 기계 코드로 바꿔주고
인터프리터는 프로그램이 실행될 때 하나씩 기계 코드로 바꿔준다.
컴파일러 코드는 더 빠르게 동작하지만, 인터프리터는 더 느리게 동작한다.
컴파일러는 편집 후에 모든 에러를 보여주지만, 인터프리터는 각 라인별 하나씩 에러를 보여준다.
컴파일러는 translation linking-loading model의 기준인 반면에 인터프리터는 Interpretation Method를 기준으로 합니다.
컴파일러는 전체 프로그램을 한 번에 하는 반면에 인터프리터는 한 줄씩 취한다.

출처:
Guru99 | https://bit.ly/3z79Q98
Q7. 캐시란 무엇인가요? 캐시의 일반적인 작동원리를 설명해주세요.
기술의 발전으로 프로세서 속도는 빠르게 증가했지만, 메모리 속도는 이를 따라가지 못했다.
서로 각각의 속도가 맞지 않으면 전체 시스템 속도는 느려진다. 이를 개선하기 위한 장치가 캐시(Cache)이다.
캐시는 CPU 칩 안에 들어가는 작고 빠른 메모리다. (비쌈)
프로세서가 매번 메인 메모리에 접근해 데이터를 받아오면 시간이 오래 걸리기 때문에 캐시에 자주 사용하는 데이터를 담아두고, 필요할 때마다 프로세서가 캐시에 접근하여 처리 속도를 높인다.
출처:
박성범 | https://parksb.github.io/article/29.html
Q8. 웹서비스에서 캐시가 적용되는 예제로는 어떤 것들이 있나요?
캐싱은 애플리케이션의 처리 속도를 높여준다. 이미 가져온 데이터나 계산된 결괏값의 복사본을 저장함으로 처리 속도를 향상시키며, 향후 요청을 더 빠르게 처리할 수 있다. 대부분의 프로그램이 동일한 데이터나 명령어에 반복해서 액세스 하기 때문에 캐싱은 효율적인 아키텍처 패턴이다.
웹 캐시: 사용자( client)가 웹 사이트(server)에 접속할 때, 정적 콘텐츠(이미지, JS, CSS 둥)를 특정 위치에 저장하여, 웹 사이트 서버에 해당 콘텐츠를 매번 요청받는 것이 아니라, 특정 위치에 불러옴으로 사이트 응답 시간을 줄이고, 서버 트래픽 감소 효과를 볼 수 있다.
웹 캐시의 종류로는,
1. Browser Caches: 브라우저 또는 HTTP 요청을 하는 클라이언트 애플리케이션에 의한 내부 디스크에 캐시
2. Proxy Caches: 네트워크 상에서 동작하는 캐시
3. Gateway Caches: 서버 앞 단에 설치되어 요청에 대한 캐시 및 분배
가 있다.
출처:
웹캐시란 무엇인가? | https://hahahoho5915.tistory.com/33
Q9. 비트맵(래스터)과 벡터 이미지의 차이점은 무엇인가요?
벡터는 점과 점 사이의 곡선으로 이미지를 구성하는 방식으로, 이미지 형태를 구성하는 다양한 선들의 좌표와 수치 정보를 바탕으로 이미지를 화면에 표시한다. ex) 일러스트 이미지(캐릭터, 아이콘)
픽셀 각각의 모든 컬러 정보를 저장하는 것이 아닌, 기본적인 점의 위치 정보 정도만 기억하면 되기 때문에 파일 크기가 작고, 이미지를 축소하거나 확대해도 이미지 손상을 주지 않는 것이 장점이다.
하지만 컬러의 자연스러운 변화와 세밀한 그림을 표현하기 어렵고, 이미지 구성 객체가 많아질수록 그래픽 처리 시간도 많이 소요된다는 단점이 있다.
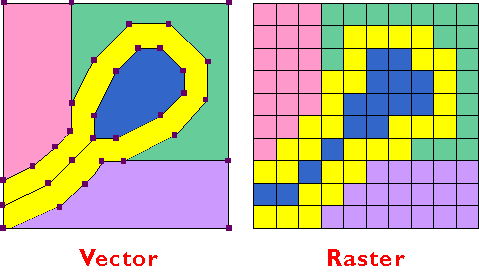
래스터 이미지는 정사각형 모양의 픽셀 수백 개가 모여 전체 이미지를 구성하는 방식으로, 비트의 지도라는 뜻의 '비트맵'이라고도 불린다. 수백 개의 점들이 모자이크처럼 모여있는 픽셀이 한 공간 안에 몇 개가 사용됐는지에 따라 이미지의 질이 달라진다.
이미지의 색상을 최대한 자연스럽게 표현하고 싶다면 많은 픽셀을 사용해야 한다. ex) 고해상도 사진, 회화작품
하지만 픽셀 각각의 컬러 정보를 모두 저장해야 하기 때문에 용량이 크고, 원본 파일 크기보다 크게 확대해서 볼 경우 화면이 계단식으로 깨져 보인다는 단점이 있다.

출처:
Wacom | https://bit.ly/3ikqTyw
Q10. 가비지 컬렉션은 무엇이며, 가비지 컬렉션 기능을 가진 언어는 무엇인가요?
가비지 컬렉션이란 메모리 관리 기법 중 하나로, 프로그램이 동적으로 할당했던 메모리 영역 중에서 필요 없게 된 영역을 해체하는 기능이다.
가비지 컬렉션 기능을 가진 언어로, 자바, C#이 있다.
출처: 위키피디아 | https://bit.ly/3v3tteW
Q11. 바이너리 파일과 텍스트 파일의 차이는 무엇인가요?
파일이란 의미 있는 정보를 담고 있으며, 이름을 가지고 있는 저장 장치상의 논리적 단위를 의미한다.
파일의 종류에 2가지가 있다.
1. 바이너리 파일
2. 텍스트 파일
바이너리 파일은 데이터의 저장과 처리를 목적으로 0과 1의 이진 형식으로 인코딩 된 파일을 가리킨다.
프로그램이 이 파일의 데이터를 읽거나 쓸 때, 데이터의 변환이 발생하지 않는다.
텍스트 파일은 사람이 알아볼 수 있는 문자열로 이루어진 파일을 가리킨다.
프로그램이 이 파일의 데이터를 읽거나 쓸 때, 포맷 형식에 따라 데이터 변환이 발생한다.
출처: TCP SCHOOL | https://tcpschool.com/c/c_io_file
OS
Q1. 프로그램(Program)에 대해서 간략하게 설명하세요.
프로그램은 컴퓨터에서 실행될 때 특정 작업을 수행하는 일련의 명령어들의 모음이다.
특정 문제를 해결하기 위해 처리 방법과 순서를 기술하여 컴퓨터에 입력되는 일력의 명령문 집합체이며
사용자의 입력에 반응하도록 구현된 일련의 명령어들로 구성되어 있다.
출처: 위키피디아 | https://bit.ly/3coafKJ
Q2. 프로세스(Process)에 대해서 간략하게 설명하세요.
프로세스는 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램이다.
여러 개 프로세서를 사용하는 것을 멀티 프로세싱이라고 하며 같은 시간에 여러 개의 프로그램을 띄우는 시분할 방식을 멀티태스킹이라고 한다.
프로그램은 일반적으로 하드 디스크 등에 저장되어 있는 실행 코드를 뜻하고,
프로세스는 프로그램을 구동하여 프로그램 자체와 프로그램의 상태가 메모리 상에 실행되는 작업 단위를 지칭한다.
ex) 하나의 프로그램을 여러 번 구동하면 여러 개의 프로세스가 메모리 상에서 실행된다.
출처: 위키피디아 | https://bit.ly/3uWLknF
Q3. 스레드(Thread)에 대해서 간략하게 설명하세요.
스레드는 어떠한 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위를 말한다.
일반적으로 한 프로그램은 하나의 스레드를 가지고 있지만, 프로그램 환경에 따라 둘 이상의 스레드를 동시에 실행할 수 있다. 이런 방식을 멀티스레드라고 한다.
멀티 프로세스와 멀티스레드는 양쪽 모두 여러 흐름이 동시에 진행되는 공통점이 있다.
멀티 프로세스에서 각 프로세스는 독립적으로 실행되며 각각 별개의 메모리를 차지하고 있다.
멀티스레드는 프로세스 내의 메모리를 공유해 사용할 수 있다.
프로세스 간의 전환 속도보다 스레드 간 전환 속도가 빠르다.

출처: 위키피디아 | https://bit.ly/3x0jJDC
Q4. 멀티 스레드와 멀티 프로세스의 차이점에 대해서 간략하게 설명하세요.
멀티 프로세스와 멀티스레드는 양쪽 모두 여러 흐름이 동시에 진행되는 공통점이 있다.
멀티 프로세스에서 각 프로세스는 독립적으로 실행되며 각각 별개의 메모리를 차지하고 있다.
멀티스레드는 프로세스 내의 메모리를 공유해 사용할 수 있다.
프로세스 간의 전환 속도보다 스레드 간 전환 속도가 빠르다.
출처: 위키피디아 | https://bit.ly/3x0jJDC
Q5. Blocking과 Non-Blocking의 차이점은 무엇인가요?
- 블로킹 vs 논블로킹 : 처리되어야 하는 (하나의) 작업이, 전체적인 작업 '흐름'을 막느냐 안 막느냐에 대한 관점
블로킹은 자신의 수행 결과가 끝날 때까지 제어권을 갖고 있는 것
논블로킹은 자신이 호출됐을 때 제어권을 바로 자신을 호출한 쪽으로 넘겨, 호출한 쪽에서 다른 일을 할 수 있도록 하는 것
좋은 예시 : https://siyoon210.tistory.com/147
출처: https://victorydntmd.tistory.com/8
Q6. Synchronous execution과 Asynchronous execution의 차이점은 무엇인가요?
- 동기 vs 비동기 : 처리해야 할 작업들을 어떠한 '흐름'으로 처리할 것인가에 대한 관점
동기는 요청과 그 결과가 동시에 일어나는 것, 함수의 결과를 호출한 쪽에서 처리
비동기는 요청과 그 결과가 동시에 일어나지 않는다는 것, 함수의 결과를 호출한 쪽에서 처리하지 않음
좋은 예시 : https://siyoon210.tistory.com/147
출처: https://victorydntmd.tistory.com/8
Q7. nodejs는 싱글 스레드인가요?
Node.js는 단순히 서버가 아니며, 자바스크립트 실행 환경에 불과하다.
단지, 서버 애플리케이션을 실행하는데 제일 많이 사용될 뿐이다.
Node.js는 Google의 Chrome V8 자바스크립트 엔진을 기본으로 동작합니다.
Single Thread 기반의 Event Loop (libuv)가 돌면서 요청을 처리하며, 시스템적으로 non-blocking I/O를 지원하지 않는 호출이 있는 경우, 이를 비동기 처리하기 위해서 내부의 Thread pool (libio)을 별도 이용하여 처리한다고 합니다.
따라서 이를 통해 병렬적으로 작업을 진행할 수 있게 됩니다! 병렬적인 작업으로 네트워크 호출이나 파일 시스템 작업, DNS 조회 등과 같이 비동기적으로 수행되는 작업은 실제로 C++로 처리됩니다.
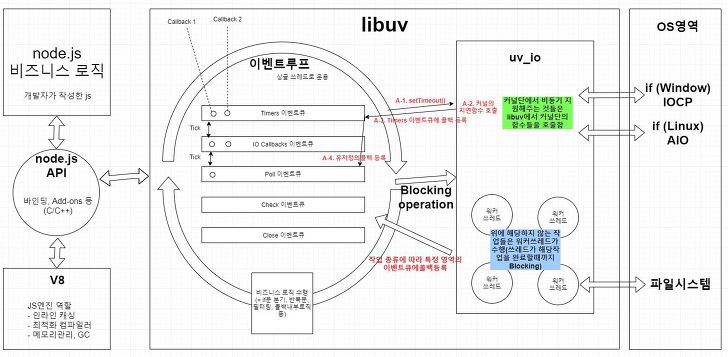
출처:
geeksforgeeks | https://bit.ly/3z6qrtJ
bsjp400.log | https://bit.ly/2RyW7ae
Q8. nodejs는 event-driven adchitecture인가요?
node.js 는 싱글 스레드 애플리케이션이지만 event와 callback을 통해 동시성을 지원할 수 있다. node.js에선 Event를 많이 사용하고, 이것 때문에 다른 비슷한 기술보다 빠른 속도를 자랑한다. node.js 기반 서버가 가동되면, 변수를 initialize 하고, 함수 선언하고 이벤트가 일어날 때까지 기다린다.
이벤트 위주 (Event-driven) 애플리케이션에서는 이벤트를 대기하는 메인 루프가 있다. event들은 listen 하고 하나의 이벤트가 감지됐을 때 callback 함수를 호출한다.
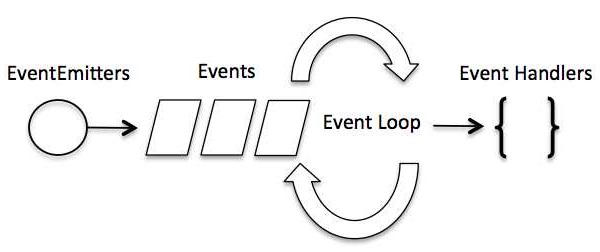
이벤트와 콜백이 비슷해 보이지만,
콜백 함수는 비동기식 함수에서 결과를 반환할 때 호출되지만,
이벤트 핸들링은 옵저버 패턴에 의해 작동된다는 점이다.
(eventlisteners 함수가 옵저버 역할: event 가 실행될 때까지 기다리다가 실행되면 listener(이벤트 처리 함수) 기능 실행됨)
출처: lygggg | https://bit.ly/34X5BiG
문자열
Q1. 문자열 하나는 몇 바이트인가요?
문자열 하나는 1바이트입니다.
1바이트는 8비트입니다.
한글이나 한자의 경우에는 1글자는 2바이트입니다.
즉, 1바이트에 16비트입니다.
출처: mwultong | https://bit.ly/2SgbXqv
Q2. 유니코드는 무엇인가요?
유니코드는 전 세계가 모든 문자를 컴퓨터에서 일관되고 표현하고 다룰 수 있도록 설계된 산업 표준입니다.
출처: 위키피디아 | https://bit.ly/3gep7MP
Q3. UTF-8과 UTF-16의 차이점은 무엇인가요?
기본 차이는 문자 하나를 표현할 때 사용할 최소 바이트를 의미한다.
전자로 문자를 표현할 때 1~4바이트만큼 필요하다.
후자로 문자를 표현할 때 2바이트(16비트), 4바이트만큼 필요하다.
두 인코딩 방식의 큰 차이는 최소 8비트가 필요하다.
최적의 상황이 필요하다면, 어떤 code point를 주로 사용하냐에 따라 선택하는 기준이 달라질 것이다.
출처: pickykang | https://bit.ly/3ps9BRD
Q4. 스타일 시트를 불러올 때 charset=utf-8을 지정해주는 이유가 무엇인가요?
유니코드 문자열(비 아스키코드)이 있을 때, utf-8로 명시적으로 선언해 utf-8 인코딩 셋을 지정한다.
(*인코딩: 문자 코드를 컴퓨터가 이해할 수 있도록 0과 1의 Binary값을 가지는 연속적인 bit형태로 mapping 해주는 작업)
출처: F.E.D | https://bit.ly/2T6TzQO
Q5. 태그에서 lang 속성을 지정해주는 이유는 무엇이며, ko-KR로 그 값을 설정해주었을 때의 속성 값의 의미는 무엇인가요?
화면 낭독기를 비롯해 음성 지원 소프트웨어가 접근했을 때 해당 언어의 정확한 발음으로 해당 콘텐츠의 이해를 도울 수 있습니다.
다양한 언어를 공부하거나 이용하는 사용자에게 있어 중요한 지표로서 작용합니다.
기본 언어는 페이지의 상단에 html 태그에 lang 속성을 이용하여 지정하고, lang의 속성 값에는 ISO 639-1에서 지정한 두 글자로 된 언어코드를 사용해야 합니다.
- 한국어의 경우 'kr'이 아닌 'ko'를 사용합니다.
출처: Nyamyamis | https://bit.ly/2T6oVam
'Interview > 모의 면접 질문 리스트' 카테고리의 다른 글
| 알고리즘 / 자료구조 모의면접 질문 리스트 (0) | 2021.06.22 |
|---|---|
| 네트워크/HTTP 모의면접 질문 리스트 (0) | 2021.06.21 |
| JavaScript 모의면접 질문 리스트(2) (0) | 2021.06.11 |
| JavaScript 모의면접 질문 리스트 (0) | 2021.06.10 |


